
Factories build instances of models, primarily for testing, but can be used anywhere. In this post I present my attempts at grading different factory libraries available for Django based on the validity of the instances that they create.
The Problem
You’re a much better programmer than me - I’m a bad programmer. I make mistakes, lots of them. I often forget to validate my instances before saving. In order for my tests to be more dependable and solid, I’d like whatever object factory I use to look after me by validating the generated instance before it reaches the database.
This is the way that I’ve been looking at Django model instances - for a single model we can imagine sets of instances which might look like:
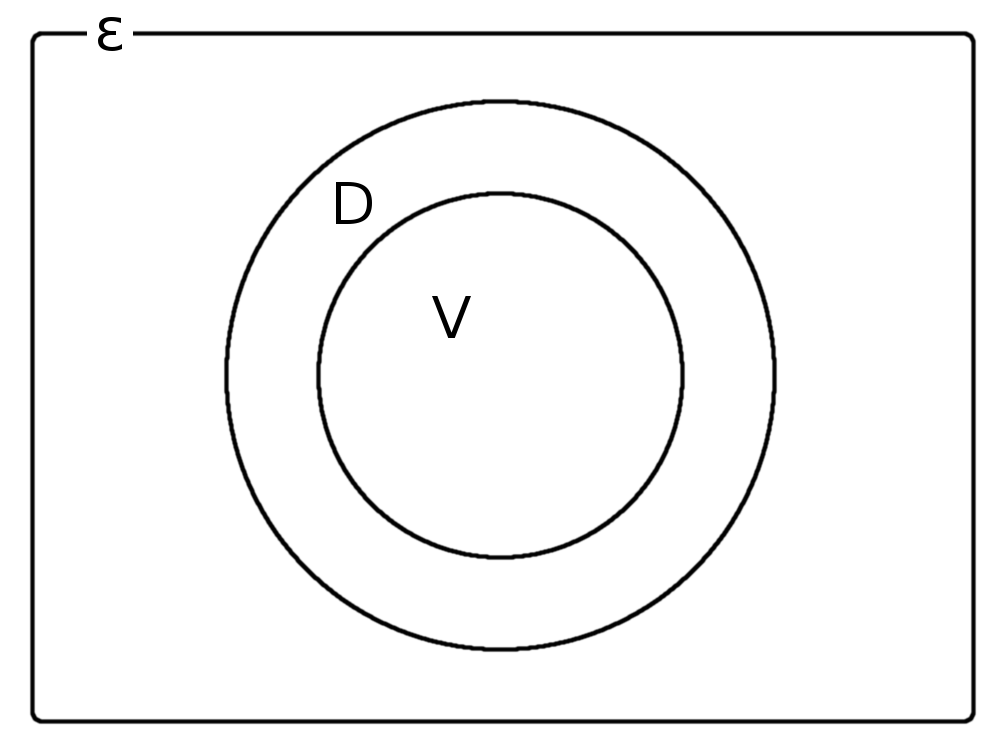
Where:
- ε: The universal set of all possible instances of this model.
- D: The set of instances that the database would consider valid. It’s interesting to note that this set might change as code is developed, tested and run on machines that have different database versions or use different databases altogether.
- V: The set of valid instances which pass full_clean. This is a subset of D.
The main issue is the set D/V of instances. These are all the instances which can be saved into the database but are considered invalid by Django.
When factories create instances that reside in this D/V set, they create instability in the system:
- If a user attempts to edit that instance through the Django Admin system, then they may not be able to save their changes without fixing a list of invalid fields.
- Test suites will be executed using model instances that should not be created during the “normal” lifetime of the application.
Possible solutions
We could argue that way in which Django does not call full_clean before it writes instances to the database is the root of the problem - I’ve previously written and spoken about this. However, this is more a “condition of the environment” and therefore something that we need to manage, rather than fix.
Also, look at it another way. Any factory that integrates with Django can inspect the target model and immediately find the constraints on each field. Therefore with Django, factory libraries have all the information they need to build a strategy for creating valid data. On top of that, Django provides the full_clean function so any generated data can also be checked for validity before it’s sent to the database. Why should we have to re-code the constraints already created for our models into our factories? This looks like duplication of work.
So let’s explore how different factory libraries deal with this problem of instances in the D/V set - the white of the fried egg in the diagram.
Factory libraries
The following factory libraries have been explored:
Factory Djoy is my factory library. It’s a thin wrapper around Factory Boy which does the hard work. I’ve indented it because it’s really a version of Factory Boy than a standalone factory library.
Test conditions
The code used to test the factory libraries is available in the Factory Audit repository. For each factory library, two factories have been created in a default state, one targeting each of the test Models:
ItemFactory: to create and save instances of plant.models.Item, a test model defined in the ‘plant’ app.
class Item(models.Model): """ Single Item with one required field 'name' """ name = models.CharField(max_length=1, unique=True)
This example has been taken from the Factory_Djoy README but with a reduced length of name down to one character to more easily force name collisions.
UserFactory: to create and save instances of the default django.contrib.auth User Model.
The goal is that each factory should reliably generate 10 valid instances of each model.
Wherever possible I’ve tried to be as explicit as possible and import the target model, rather than refer to it by name as some factories allow.
Gradings
Each factory library has been graded based on how its default configuration behaves when used with the Item and User models.
The gradings are based on the definition of “valid”. Valid instances are ones which will pass Django’s full_clean and not raise a ValidationError. For example, using the ItemFactory a generated item passes validation with:
item = ItemFactory()
item.full_clean()
The gradings are:
 RED - Factory creates invalid instances of the model and
saves them to the database. These are instances in the D/V set.
RED - Factory creates invalid instances of the model and
saves them to the database. These are instances in the D/V set. YELLOW - Factory raises an exception and does not save any
invalid instances. Preferably this would be a ValidationError, but I’ve
also allowed IntegrityError and RunTimeError here.
YELLOW - Factory raises an exception and does not save any
invalid instances. Preferably this would be a ValidationError, but I’ve
also allowed IntegrityError and RunTimeError here. GREEN - Factory creates multiple valid instances with no
invalid instances created or skipped. Running factory n times generates
n valid instances.
GREEN - Factory creates multiple valid instances with no
invalid instances created or skipped. Running factory n times generates
n valid instances.
The tests on each of the factories have been written to pass when the factory behaves to the expected grade. For example, the test on Factory Djoy’s ItemFactory expect that it raises ValidationError each time it’s used and is therefore YELLOW grade.
Results
Original results
| Library | ItemFactory | UserFactory |
|---|---|---|
| Django Fakery | RED |
YELLOW |
| Factory Boy | RED |
RED |
| Factory Djoy | YELLOW |
GREEN |
| Hypothesis[django] | RED |
RED |
| Mixer | GREEN |
GREEN |
| Model Mommy | YELLOW |
GREEN |
Update
Thanks to Piotr and Adam who pointed out some issues with my grading system.
Adam pointed out that collisions are still collisions, even if they are unlikely. Therefore, even if factories are employing fantastic strategies for generating valid data, their generated instances should still be run through full_clean before save.
I agree with this opinion and think that calling full_clean on every instance creates the opportunity for two benefits, over and above asserting that every instance is valid:
- If a factory raises ValidationError with information on what failed it will always be helpful to the developer who is fixing the broken test run.
- If invalid data is found, this would create an opportunity for a factory to adjust failing fields so that valid data can be saved and the test run will not be interrupted.
I’ve added a “Uses full_clean” field to evaluate each factory and capture this information.
Piotr pointed out that the results of the grading are inconclusive since I don’t agree with the results. For example, in the original results Mixer is the only library that has GREEN GREEN and therefore we would assume that it is the best of the factories tested. However, that’s not the case, since I found it hard to use and its exception bubbling was also intrusive.
I’ve added the “Ease of use” grading to capture this information based on my experience working with each factory.
New gradings
- Uses full_clean:
- RED - Not instance of full_clean in the factory code base.
- YELLOW - Factory code base includes full_clean in the
test suite only.
- GREEN - Factory tests every generated instance with
full_clean.
- Ease of use:
- RED - Do not bother trying. Too difficult to use.
- YELLOW - Some pain may be experienced. You might struggle to
install, need to adjust your workflow, packages, etc.
- GREEN - Easy to install. Clean API.
Updated results
Results with additional “Uses full_clean and “Ease of use” information:
| Library | ItemFactory | UserFactory | Uses full_clean | Ease of use |
|---|---|---|---|---|
| Django Fakery | RED |
YELLOW |
RED |
GREEN |
| Factory Boy | RED |
RED |
RED |
GREEN |
| Factory Djoy | YELLOW |
GREEN |
GREEN |
GREEN |
| Hypothesis[django] | RED |
RED |
YELLOW |
GREEN |
| Mixer | GREEN |
GREEN |
RED |
YELLOW |
| Model Mommy | YELLOW |
GREEN |
RED |
GREEN |
Notes about each library
Grading each library was often harder than I thought it would be because many don’t fall into one grading or another. Where that has happened I’ve noted it below.
Django Fakery
ItemFactory
REDUnfortunately, Django Fakery does not recognise that only one character is allowed for the Item model’s name field. It uses Latin words from a generator which are saved by the default SQLite database and are invalid because they are too long.
UserFactory
YELLOWIn order to create User instances Django Fakery also uses the Latin generator which collides often. This means that IntegrityError is raised when collisions occur, but any Users created are valid.
Factory Boy
ItemFactory
REDCreates invalid instance of Item which has no name and saves it.
UserFactory
REDCreates User with invalid username and password fields and saves it.
Factory Boy has no automatic strategies used for default factories and so it fails this test hard. If the library was extended to call full_clean for generated instances before saving then it could be upgraded to YELLOW.
Factory Djoy
ItemFactory
YELLOWCalls full_clean on the Item instance created by Factory Boy which it wraps. This raises ValidationError and the Item is not saved.
UserFactory
GREENCreates valid instances using a simple strategy Unique usernames are generated via Faker Factory which is already a requirement of Factory Boy. full_clean is called on the generated instance to catch any collisions in the strategy and on collision, a new name is generated and retried.
Factory Djoy contains only one simple strategy for creating Users. It has no inspection ability to create strategies of its own based on Models.
Hypothesis[django]
ItemFactory
REDUserFactory
REDHypothesis’s Django extra does not reliably create instances of either model because it’s example function does not reliably generate valid data. In the case that an invalid example is generated it is skipped and the previous example is used.
Interestingly, Hypothesis creates User instances that Django considers to have invalid email addresses.
Uses “full_clean“
YELLOWHypothesis’s code base currently includes a single instance of full_clean. This is in its test suite to assert that instances built are valid. However, it doesn’t call full_clean on generated instances during its normal operation.
Mixer
ItemFactory
GREENMixer appears to inspect the Item model and generates a very limited strategy for generating names. Unfortunately it runs out of instances around 23, even though there are hundreds of characters available.
UserFactory
GREENEase of use
YELLOWMixer helpfully raises Runtime error if a strategy can’t generate a valid instance. However, it echoes this to the standard out, which is annoying and really confused me when I was first using it because exceptions appear on the terminal even though all tests have passed.
It uses an old version of Fake Factory which meant that its tests had to be extracted into a second test run that occurs after a pip-sync has taken place. I found this the hardest factory library to work with.
Model Mommy
ItemFactory
YELLOWThere is no method used to create unique values so there are collisions when there are a small number of possible values. Items that are created are valid.
UserFactory
GREENModel Mommy’s random text strategy works here for username and the random strings are unlikely to collide.
Model Mommy depends on its strategies to create valid data and does not call full_clean meaning that IntegrityError can be raises when collisions occur. It could be argued that it should be downgraded to YELLOW because IntegrityError is raised.
And the winner is?
What is the best factory to use? This is a really hard question.
These factory libraries generally consist of two parts and different libraries do each part well.
- Control / API: Personally I really like the Factory Boy API and how it interfaces with Django. I’m happy with the Factory Djoy library because it provides the certainly of calling full_clean for every created instance on top of the Factory Boy API.
- Data strategy: I’m excited by Hypothesis and its ability to generate test data.
My current advice is to use Factory Djoy, or wrap your favourite factory in a call to full_clean.
Yes, there is a performance overhead to calling full_clean but my opinion is that eliminating the D/V set of invalid instances is worth the effort and makes the test suite “fundamentally simpler” [1].
My future thinking is that if Hypothesis can improve its interface to Django it could be the winner.
Resources
- Factory audit repository: Contains the research work - factories and tests for each factory library. Pull requests very welcome - especially if they add a new factory library or fix a test.
- Slides: From my presentation of these results at the London Django October meetup.
- Video: Available via the Skills Matter website.
- Thanks to Adam for pointing out the collisions issue which you can hear in the video around 20 minutes in. Even if collisions are unlikely, they can still be a problem. Check out his Factory Boy post.
- The 15th October update to the post is visible as a Pull Request on the blog’s repository.
Happy fabricating!
| [1] |
Taking a few percent hit, going a little slower, in order to do something that’s just fundamentally simpler” Pycon UK 2016: Python and the Glories of the UNIX Tradition Brandon Rhodes, Pycon UK 2016 |