
It started with a Tweet
Over the weekend I spotted a tweet from Oliver…
To squash features into develop, or not to squash features into develop?
— Oliver Caldwell (@OliverCaldwell) November 15, 2013And I jumped straight in with…
@OliverCaldwell Squash, but keep detailed commit messages. Unless you have a particular use-case / reason not to.
November 17, 2013
Then, as part of our following conversation, I drew a picture:
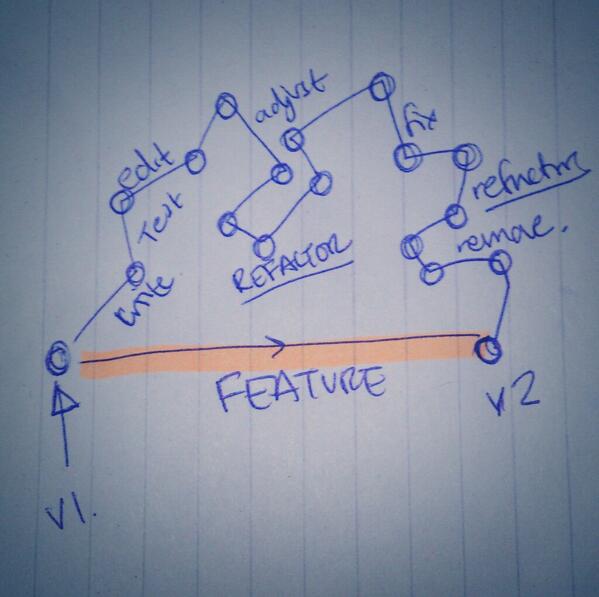
This is how I see it. Better to keep the direct route rather than the “how we got here”.
November 18, 2013
But…
It’s about more than just squashing
What I realised while writing this post and experimenting with git is that the issue is not as simple as “Squash? Yes / No?”
Variables to consider include:
- How you record your commit messages on your squashed commit. This effects the impact of history loss - good commit messages and or external ticketing / dev tracking mean it’s less important.
- Whether you push your feature branches for other developers, or between your dev boxes, to share. Do you need to keep the shared history between machines?
- The velocity of your project. How long do you need to keep history for? Do bugs show up regularly?
TL;DR Simple project. Squash = Yes
For a simple project with no sharing between devs required and regular releases, then squashing features seems like a good idea if you:
- Keep detailed commit messages when you squash.
- Use git rebase to squash your features’ commits into a candidate branch and merge that in to dev or master depending on your SCM strategy.
- Only push your squashed features to keep origin clean and easy to understand.
- Keep your feature branches if you want. But, if you delete them git will keep your commits in the reflog for 30 days by default.
Keeping a detailed history
One of the issues that Oliver raised was about losing history.
@jamesfublo I suppose so. Squashing just feels like you're killing off that fine grained history, like when was that two line change made.
— Oliver Caldwell (@OliverCaldwell) November 18, 2013So, since I advocate squashing and branch deletion, I’m therefore suggesting that the reflog is used to recover detailed history in the local repository if required.
So let’s explore how much history is actually kept…
Reflog is a mechanism to record when the tip of branches are updated.
This means that…
Every commit that every branch in your local repostitory has ever pointed to is kept in the reflog.
And this even includes branch switching…
HEAD reflog records branch switching as well.
Sounds very warm and cozy, BUT there are conditions, so let’s do a practical experiment with a test repository.
Experiment: Squashing with rebase and keeping history
Make a repository with an initial commit.
$ git init
Create a README.md file and put a line of text into it and commit - this commit is called A.
$ cat > README.md
First line of readme file
^C
$ git add README.md
$ git commit
Current git tree status:
A <-master
Work on feature
In a new branch, we create a feature to update the README with two new lines and to delete the first line.
$ git checkout -b feature-a
# First feature commit (B)
$ cat >> README.md
Add a second line
^C
$ git add README.md
$ git commit
# Second feature commit (C)
$ cat >> README.md
Add a third line
^C
$ git add README.md
$ git commit
# Third feature commit (D)
$ vim README.md
# Remove first line and save
$ git add README.md
$ git commit
Current git tree status:
A <-master \ B--C--D <-feature-a
Check progress in reflog
Checkout master.
$ git checkout master
Let’s check the reflog.
$ git reflog
8e48d1d HEAD@{0}: checkout: moving from feature-a to master
262057a HEAD@{1}: commit: D: Remove first line
9efbf73 HEAD@{2}: commit: C: Add a third line
f2503d5 HEAD@{3}: commit: B: Add a second line
8e48d1d HEAD@{4}: checkout: moving from master to feature-a
8e48d1d HEAD@{5}: commit (initial): Make readme
Newest stuff pops out first:
- HEAD@{0} - Checkout from feature-a to master is recorded.
- HEAD@{1} to HEAD@{3} - our feature-a commits (D, C and B).
- HEAD@{4} - Checkout of the feature-a branch.
- HEAD@{5} - Initial commit.
Squash commits into candidate branch
feature-a is ready to bring into master. Let’s first cleanup our history by doing an interactive rebase. We use a candidate branch for this work because it’s a nice safety net which can help with testing.
$ git checkout feature-a
$ git checkout -b feature-a-candidate
Current git tree status:
A <-master \ B--C--D <-feature-a <-feature-a-candidate
$ git rebase --interactive master
Let’s squash our three commits into one.
pick f2503d5 B: Add a second line squash 9efbf73 C: Add a third line squash 262057a D: Remove first line
And now we merge together the three commits, describing the activity that took place. We keep the messages so that history is clean, but informative. We also include a reference to the ticket we are working against:
Updating README.md as per #ticket * Add a second line * Add a third line * Remove first line
Check reflog again:
$ git reflog
d0445b2 HEAD@{0}: rebase -i (finish): returning to refs/heads/feature-a-candidat
d0445b2 HEAD@{1}: rebase -i (squash): Updating README.md as per #ticket
362b6ef HEAD@{2}: rebase -i (squash): # This is a combination of 2 commits.
f2503d5 HEAD@{3}: checkout: moving from feature-a-candidate to f2503d5
262057a HEAD@{4}: checkout: moving from feature-a to feature-a-candidate
The reflog shows us that there is a new commit d0445b2, we’ll call this E. This is the commit that results from the rebase and leaves the tree looking like:
A <-master |\ | B--C--D <-feature-a \ \ E <-feature-a-candidate
This is a good stage to test everything and to check that your tests are what you expect them to be, ensure that no information has been lost.
Merge onto master
The new commit E is the patch for our feature which we now merge onto master.
$ git checkout master
$ git merge feature-a-candidate master
Updating 8e48d1d..d0445b2 Fast-forward README.md | 3 ++- 1 file changed, 2 insertions(+), 1 deletion(-)
The tree:
A--E <-master <-feature-a-candidate \ B--C--D <-feature-a
Push
At this stage the feature would usually be pushed to a branch on origin.
$ git push origin master
Note that we’ve only shared the squashed E commit, not B, C or D in the feature-a branch.
Cleanup
We can then cleanup our working branches. First the candidate.
$ git branch -d feature-a-candidate
This leaves us with a tree like:
A--E <-master \ B--C--D <-feature-a
Keeping history
As Oliver noted, the feature-a branch can just be kept by the developer in their local repository to preserve the full history - that is certainly an option.
@jamesfublo I suppose you can still keep the unsquashed branches in the repository. I never used to squash, but I might start.
— Oliver Caldwell (@OliverCaldwell) November 18, 2013However, I prefer a clean working repository so I like to delete the feature-a branch.
Clean up the feature branch
When deleting the feature-a branch git requires the -D flag to force the deletion. git does not work out that E is equal to B, C and D combined, so thinks that history could be lost.
$ git branch -D feature-a
Deleted branch feature-a (was 262057a)
This leaves a tree like:
A--E <-master \ B--C--D
B, C and D are now hanging commits
Check reflog.
$ git reflog
This is a part of it:
...
262057a HEAD@{12}: commit: D: Remove first line
9efbf73 HEAD@{13}: commit: C: Add a third line
f2503d5 HEAD@{14}: commit: B: Add a second line
...
The development commits from the feature development are still available and could be checked out into detached HEAD state and inspected, played with, rebranched. Let’s try that.
$ git checkout 262057a
Now play and explore as much as you want.
When you’re ready, move back to master.
$ git checkout master
And git warns us that we’ve left behind our hanging commits:
Warning: you are leaving 3 commits behind, not connected to any of your branches: 262057a D: Remove first line 9efbf73 C: Add a third line f2503d5 B: Add a second line If you want to keep them by creating a new branch, this may be a good time to do so with: git branch new_branch_name 262057a
How long are hanging commits kept?
But how long will these unreachable commits hang around for?
We can decide!
Hanging commits are removed from the local repository by garbage collection, known as gc, or by manual removal.
There are various settings which gc will use to determine which commits should be cleaned before the repository is repacked.
gc.reflogExpireUnreachable tells gc how long hanging commits should be left in the repository. Default value is 30 days. Adjust this to a value that you feel comfortable with. You can make that setting on any of the normal levels - global, system or local.
Hey - you want to keep all history in the reflog for ever? Here’s a setting:
[gc]
reflogExpire = never
reflogExpireUnreachable = never
I’m happy with the 30 day default myself!
For more detailed explanation, checkout the Configuration section of the git-gc man page.
A manual clean
Just for experimention, I tried to clean the repository of the B, C and D hanging commits. This was challenging because my default settings prevented reflog and gc from performing the clean, however I found this SO answer helpful.
$ git reflog expire --all --expire-unreachable=0
$ git repack -A -d
Repacking occurred. Now check reflog.
$ git reflog
d0445b2 HEAD@{0}: merge feature-a-candidate: Fast-forward
8e48d1d HEAD@{1}: checkout: moving from feature-a-candidate to master
d0445b2 HEAD@{2}: rebase -i (finish): returning to refs/heads/feature-a-candidat
d0445b2 HEAD@{3}: checkout: moving from master to feature-a
8e48d1d HEAD@{4}: commit (initial): Make readme
There are now only two commits in the repository:
- 8e48d1d - Initial commit A @ 1 and 4.
- d0445b2 - Feature commit E made by the rebase @ 0, 2 and 3
The cleaned repository now looks like:
A--E <-master
So fresh and so clean!
Summary
At the end of the day, the dev team (even if that’s just you on a weekend project) decides how best to keep history and share features.
My general solution is for:
- Squashed single-commit features.
- Detailed commit messages created at squash-time.
- Devs keep more history locally, either with branches or in a long-life reflog.
- Devs backup their repositories and don’t rely on origin.
Remember there can be a full 30 day history (or longer depending on the gc.reflogExpireUnreachable setting) in the local repo which hasn’t been pushed to origin. It’s this history that could save your bacon one day - so consider backing it up!
Happy source code management!
Update 23/08/2018
See also this comment on GitHub from Curt J. Sampson with some great points about when not to squash. One helpful excerpt:
I think of a set of commits I’m proposing for master branch as a story I’m telling to the other developers. Make the story as clear as possible, divided up into reasonably small chunks where you can do so. This will make other developers love, rather than hate, reviewing your code.
Thanks Curt - spread the love!
Update 06/01/2019
The Twitter account that I used in my conversations with Oliver above has been deleted. I’ve replaced the links to tweets with the original content.